論文解説 LLMを使ったシステマティックレビュー
要約
タイトル: Can large language models replace humans in the systematic review process? Evaluating GPT-4's efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages
著者: Qusai Khraisha, Sophie Put, Johanna Kappenberg, Azza Warraitch, Kristin Hadfield
論文のURL: https://arxiv.org/abs/2310.17526
この論文の解説です。
論文発表日: 26 Oct 2023
専門外の人でも分かるような説明
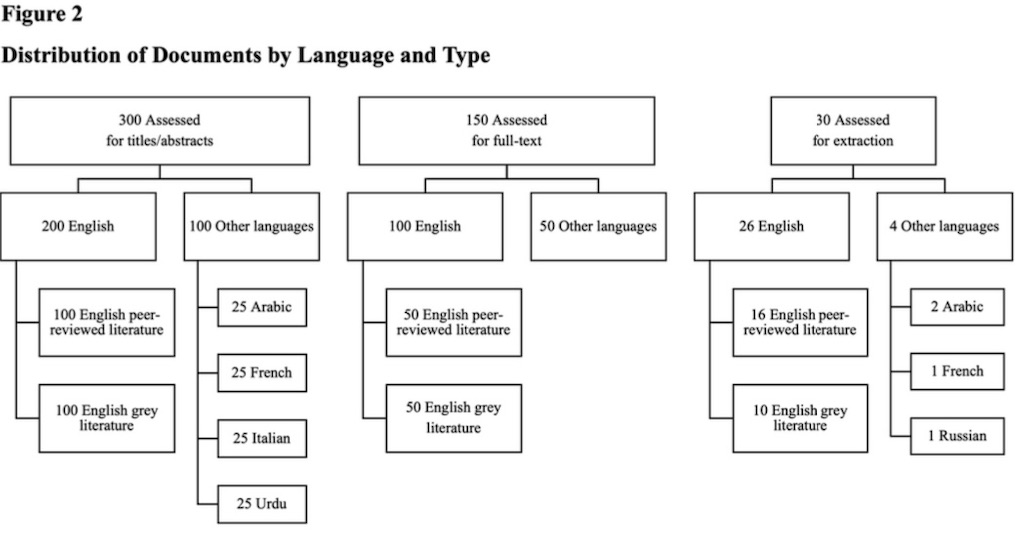
この研究は、大規模な言語モデル(LLMs)が人間の役割を代替できるかどうかを評価するものです。特に、学術文献やグレー文献のシステマティックレビュー(網羅的な文献調査)のプロセスにおいて、GPT-4の効果を評価しています。システマティックレビューは、実践、研究、政策の指針として非常に重要ですが、時間がかかることが多いです。この研究では、LLMsがこのプロセスを高速化し、自動化するための方法を提案しています。
要約
システマティックレビューは、実践、研究、政策の指針として重要ですが、しばしば遅く、労力を要するものです。LLMsは、システマティックレビューを高速化し、自動化する方法を提供する可能性があります。しかし、その性能は、人間との包括的な比較がなされていないため、GPT-4の性能を評価するためのこの事前登録研究が行われました。GPT-4は、ほとんどのタスクで人間と同等の精度を持っていましたが、結果は偶然の一致やデータセットの不均衡によって偏っていました。信頼性の高いプロンプトを使用した場合、GPT-4の性能は「ほぼ完璧」でした。GPT-4を使用してシステマティックレビューを行う場合、現在、十分な注意が必要であることが示されましたが、信頼性の高いプロンプトの下で特定のシステマティックレビュータスクを提供する場合、LLMsは人間の性能に匹敵することが示唆されています。
従来とは異なるこの論文の新しい点
この研究は、GPT-4という最新の大規模な言語モデルを使用して、システマティックレビューのプロセスにおけるその効果を評価しています。特に、タイトル/抄録のスクリーニング、全文レビュー、データ抽出などのタスクにおけるGPT-4の能力を評価しています。
課題点
- GPT-4のシステマティックレビューのタスクにおける性能をさらに向上させるための新しい手法や技術の開発が必要です。
- GPT-4の性能を評価する際のデータセットの不均衡や偶然の一致などの課題を克服するための研究が必要です。
 | 深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版 (EXAMPRESS) [ 一般社団法人日本ディープラーニング協会 ] 価格:3,080円 |
![]()