GPT-4o Mini
現代のAI技術は日々進化を遂げていますが、その中でも特に注目を集めているのが、OpenAIが提供する「GPT-4o Mini」です。高性能かつコスト効率の良いこの小型モデルは、幅広いビジネスアプリケーションに適用可能であり、その技術的革新とビジネスインパクトは計り知れません。本記事では、GPT-4o Miniの概要から技術的革新、モデル評価スコア、そしてビジネスインパクトに至るまでを詳しく解説し、その強みと弱みについても客観的に評価します。AIに興味のある方はもちろん、最新の技術動向を把握したいビジネスパーソンにも必見の内容です。
この記事はこちらのページを参考に書いています。 https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
目次
- GPT-4o Miniの概要
- モデルの技術的革新
- モデルの圧縮技術
- データ最適化
- 蒸留技術
- 推論速度の向上
- ハードウェアとインフラの最適化
- モデル評価スコア
- Reasoning tasks
- Math and coding proficiency
- Multimodal reasoning
- GPT-4o Miniの強みと弱み
- 評価ベンチマークの説明
- ビジネスインパクト
- コスト削減
- スケーラビリティ
- 新しいビジネスモデルの創出
- 市場への影響
- まとめ
1. GPT-4o Miniの概要
- 名称: GPT-4o Mini
- 提供元: OpenAI
- 目的: コスト効率の良いインテリジェンスの提供
- 特徴:
- 小型モデルの採用
- 高いパフォーマンスと低コストを両立

2. モデルの技術的革新
2.1 モデルの圧縮技術
- 技術概要:
- モデルサイズの圧縮により、計算リソースを削減
- 量子化とプルーニング技術を活用
- 量子化:
- 低精度の数値表現を使用し、モデルサイズを縮小
- パフォーマンスの低下を最小限に抑える
- プルーニング:
- 不要なネットワーク接続を削減し、モデルを簡素化
- 実行速度の向上
2.2 データ最適化
2.3 蒸留技術
- 知識蒸留:
- 大型モデルの知識を小型モデルに転移
- パフォーマンスを保持しつつモデルサイズを縮小
- 技術詳細:
- 蒸留教師モデルの選択
- 蒸留プロセスのチューニング
2.4 推論速度の向上
3. ハードウェアとインフラの最適化
エッジデバイスの活用:
クラウドリソースの最適化:
- クラウドインフラの効率的な利用
- リソーススケーリングとコスト管理
インフラの冗長性と可用性:
- 高可用性システムの設計
- フォールトトレランスと自動リカバリ
- フォールトトレランス:
- システムが一部の故障に対しても正常に動作し続ける能力
- 冗長なハードウェアやソフトウェア構成により、システム障害時の影響を最小限に抑える
- 自動フェイルオーバー機能で、障害発生時に即座にバックアップシステムへ切り替える仕組み
4. モデル評価スコア
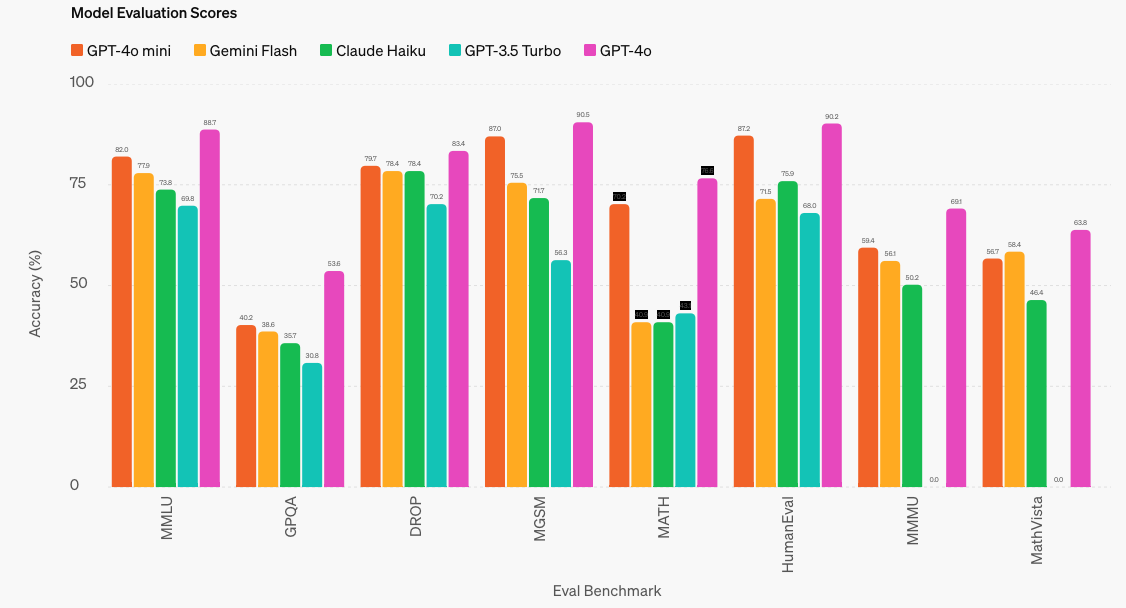
4.1 Reasoning tasks
4.2 Math and coding proficiency
- 数学的推論 (MGSM):
- コーディング性能 (HumanEval):
4.3 Multimodal reasoning
4.4 GPT-4o Miniの強みと弱み
強み:
- 高い推論能力: MMLUで82.0%のスコアを達成し、他の小型モデルを上回る。
- 優れた数学的推論とコーディング能力: MGSMで87.0%、HumanEvalで87.2%のスコアを記録し、これらの分野で強力なパフォーマンスを発揮。
- マルチモーダル推論の強化: MMMUで59.4%のスコアを獲得し、他の小型モデルに比べて優れている。
弱み:
- 特定タスクの改善余地:
- リソース依存:
- 具体的な課題:
- モデルの高性能を維持するためには、最新の高性能なハードウェアが必要となる場合があり、特に低リソース環境ではパフォーマンスが劣ることがある。
- 改善の方向性:
- モデルのさらなる軽量化と最適化
- リソースが限られた環境でも動作可能なアルゴリズムの開発
- 具体的な課題:
4.5 評価ベンチマークの説明
- MMLU (Massive Multitask Language Understanding):
- 総合的な言語理解能力を評価するためのベンチマーク。幅広いトピックにわたる複数のタスクを含む。
- GPCQA (General Purpose Commonsense Question Answering):
- コモンセンスに基づく質問応答能力を評価するベンチマーク。一般的な知識と論理的推論をテストする。
- DROP (Discrete Reasoning Over Paragraphs):
- MGSM (Math General Skills Measurement):
- 数学的スキルを評価するベンチマーク。数学的推論と問題解決能力をテストする。
- MATH:
- 数学的問題解決能力を評価するベンチマーク。高度な数学的スキルを測定する。
- HumanEval:
- プログラムの生成と評価を目的としたベンチマーク。コーディングタスクに対するモデルの能力を評価する。
- MMMU (Multimodal Multitask Unified Benchmark):
- マルチモーダル推論能力を評価するベンチマーク。テキストとビジョンの両方を含む複数のタスクをテストする。
- MathVista:
- 視覚的な数学的問題解決能力を評価するベンチマーク。視覚
情報と数学的推論を組み合わせたタスクを含む。
4.6 Reasoning tasks、Math and coding proficiency、Multimodal reasoningの違い
Reasoning tasks:
Math and coding proficiency:
- 概要: 数学的推論とプログラミング能力を評価。
- 評価対象: MGSM、MATH、HumanEvalなどのベンチマーク。
- 特長: 数学的問題解決能力やコーディングスキルが試される。
Multimodal reasoning:
- 概要: テキストとビジョンを組み合わせたマルチモーダル推論能力を評価。
- 評価対象: MMMU、MathVistaなどのベンチマーク。
- 特長: テキストと視覚情報を統合した総合的な理解と推論能力が試される。
5. ビジネスインパクト
5.1 コスト削減
5.2 スケーラビリティ
- 拡張性:
- 多様な業界での応用可能
- システム拡張に伴うパフォーマンス維持
- 柔軟性:
- カスタマイズ可能なソリューション提供
- クライアントニーズに応じた調整
5.3 新しいビジネスモデルの創出
- インテリジェントアシスタント:
- 効率的なカスタマーサポートの実現
- 自動応答システムの向上
- リアルタイムデータ分析:
- 予測モデルとリアルタイム分析の導入
- ビジネスインサイトの提供
5.4 市場への影響
- 市場競争力の強化:
- コストパフォーマンスに優れたソリューション提供
- 競争優位性の確立
- 新興市場の開拓:
- 新規アプリケーションと市場ニーズの対応
- グローバル展開の可能性
6. まとめ
- GPT-4o Miniの意義:
- 小型でありながら高性能
- コスト効率の高いインテリジェンスソリューションを提供
- 今後の展望:
- 広範なビジネスアプリケーションへの応用
- 市場のニーズに応じた継続的な技術革新
機械学習徹底理解 G検定 概要(前半)
 | ディープラーニングG検定公式テキスト/日本ディープラーニング協会/山下隆義/猪狩宇司【3000円以上送料無料】 価格:3080円 |
![]()
 | ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[第2版] [徹底解説 良質問題 模試(PDF)] [ ヤン ジャクリン ] 価格:2970円 |
![]()
![]()
![]()
![]()