論文解説 ファインチューニングとハルシネーションの関係
解説する論文
- タイトル: Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
- 著者: Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, Jonathan Herzig
- 論文のURL: arXivリンク
- 発表日: 2024年5月9日
専門外の人でも分かる解説
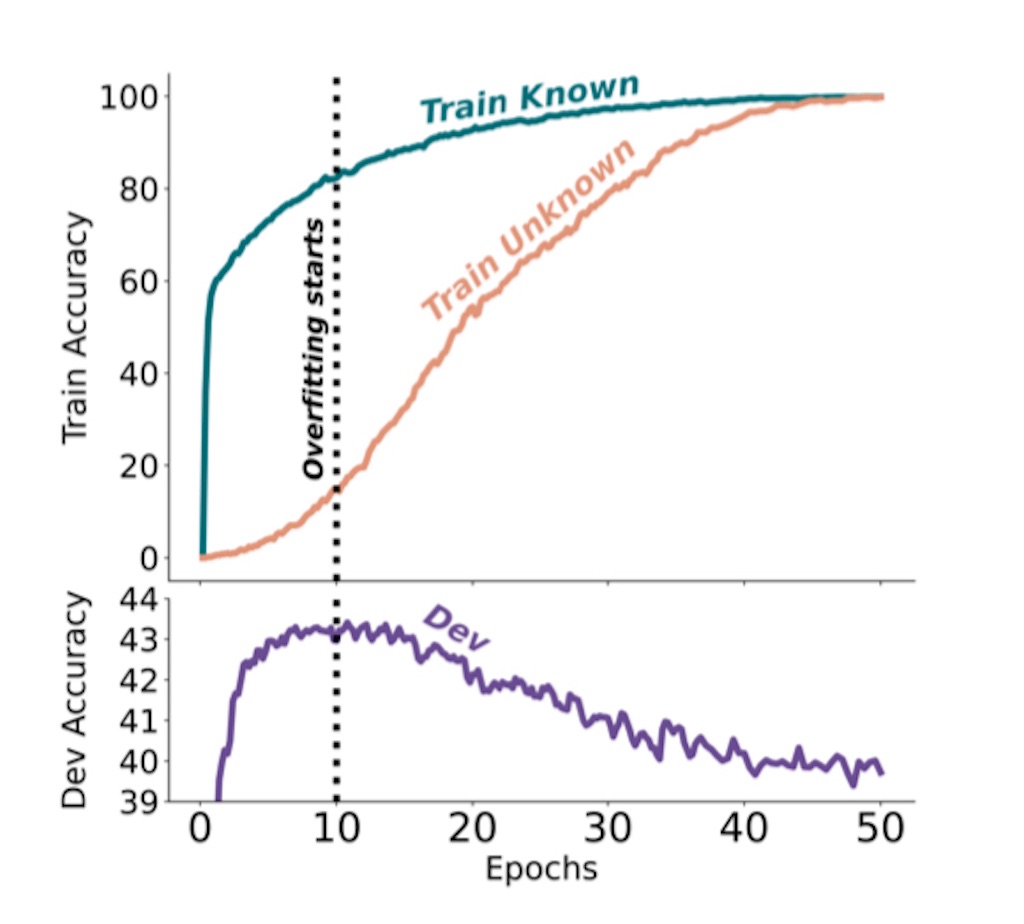
この研究は、新しい知識でファインチューニングされた大規模言語モデル(LLMs)が事実と異なる回答を生成する傾向、すなわち「幻覚」を促進するかどうかを探ります。ファインチューニングとは、特定のタスクやデータセットにモデルを適応させることを指します。
要約
この論文の新しい点
研究者たちは、新しい知識を導入するファインチューニング例の割合を変えることにより、モデルが新しい事実をどのように学習し、使用するかの実験を行いました。これにより、モデルが新しい知識を効果的に学ぶのが遅いこと、そしてその知識が最終的に学ばれるとモデルが幻覚を生じる傾向が増すことが明らかになりました。
課題点
この研究は、新しい知識を導入するファインチューニングが持つリスクを示していますが、どのようにしてこれらのリスクを最小限に抑えるかについての具体的な解決策は提供していません。
展望
将来的には、大規模言語モデルが新しい知識を取り入れる際のリスクを軽減しつつ、正確性を保持する方法の開発が求められます。また、モデルが新しい知識をどのように処理し、統合するかの理解を深める必要があります。
 | 深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版 (EXAMPRESS) [ 一般社団法人日本ディープラーニング協会 ] 価格:3,080円 |
![]()